Innehållsförteckning
Inledning
Rapporten Förstudie: Interoperabel data- och informationsförsörjning mellan samhällssektorer för omdömesgilla beslutsstöd är en förstudie som syftar till att bidra med underlag till Trafikverkets kommande FOI-plan 2023-2028 inom det tematiska området ”nästa generations beslutsstöd”, där ändamålet är att övergripande beskriva problemområdet och inrikta kommande forskningsprojekt som söker finansiering av Trafikverket till relevanta ansökningar med hög nyttiggörande potential.
Bakgrund
Varje samhällssektor är en egen kunskapsdomän och system bestående av informationssilor, fragmenterade processer och leveranser, regleringar, lagar, kultur med mera, där tillgången till enhetlig standardiserad och strukturerad data är en bristvara. Detta skapar komplexa beroenden och inlåsningar som medför stora hinder för en datadriven utveckling inom och mellan samhällssektorer. Tidigare forskningsprojekt, FOI: metod för samverkan och externt värdeskapande öppna data identifierade betydande problem att uppnå interoperabilitet inom transportsektorn. Projektet intervjuade ett halvt dussin avtalskunder till Trafikverket inom tågtrafiken som bland annat beskrev en verklighet där informationsutbytet för koordinering av trafikavvikelser skedde manuellt, och där användare kopierade information från ett system till ett annat, skickade e-post, samt använde telefonkontakt för att koordinera ersättningstrafik och prognostisera när planerad trafik kunde återupptas. Intervjuerna genomfördes 2016 och lite verkar ha förändrats med tanke på dagens fragmenterade systemstöd och bristande harmonisering av data och informationsförsörjning för att analysera delar av transportsystemet, såsom trafikprognoser, underhållsstatus, kapacitetsberäkning, med mera, som består av ett 20-tal system och program för att skapa aktuella lägesbilder av specifika järnvägssträckningar. Liknande utmaningar existerar inom andra samhällssektorer, vilket skapar ytterligare dimensioner till utmaningen att lösa vidareutnyttjande av data, information och domänkunskapsutbyte mellan samhällssektorer.
Dagens manuella datahantering med en uppsjö av fragmenterade systemstöd och datakällor utgör hinder för realtidsbaserade lägesbilder och nyttjande av framväxande digital teknologi som AI, digitala tvillingar, 3D-visualisering och liknande verktyg som behöver strukturerad data, baserat på mänsklig kunskap och erfarenhet för att skapa insiktsfulla prognoser och beslutsstöd. Detta är avgörande för att exempelvis nyttja AI-teknologi bortom enklare mönsterigenkänning av ostrukturerade datamängder för att automatisera elementära databehandlingsrutiner. Om sömlöst vidareutnyttjande av data och information enbart varit ett tekniskt problem hade dessa hinder och barriärer troligen varit åtgärdade eftersom förmågan att tillämpa liknande teknologier redan existerar. Detta tyder på att problemområdet behöver utforskas från flera olika perspektiv som exempelvis beaktar teorier om komplexa system, mänsklig kognitiv begränsning, systematisk hantering av kunskap, etik, lagar och värderingar mellan människa och maskin för att skapa tilltro och möjliggöra omdömesgill digital samhällsutveckling.
Problembeskrivning
Dagens fragmenterade och silobaserade systemstöd inom traditionella verksamheter och sektorer utgör utmaningar för att skapa sömlöst vidareutnyttjande av data, information och kunskapsöverföring mellan samhällssektorer som är en förutsättning för en datadriven utveckling grundad på mänsklig erfarenhet och demokratiska principer. Sömlös data- och informationsförsörjning samt domänkunskapsutbyte mellan samhällssektorer är betydelsefullt för att korrelera och kombinera dataströmmar för att skapa underlag för att fatta omdömesgilla och skyndsamma beslut om en ombytlig mångfacetterad socioteknisk samhällsutveckling där transportsystemet är en integrerad del. Förstudien ämnar skapa en övergripande tematisk indelning över dessa utmaningar och hur de är sammanlänkade för att ge förslag på åtgärder och problemområden som behöver beforskas inom temat “nästa generations beslutsstöd”.
Tematisk indelning av problemområdet
Digital transformation och kunskapshantering
Sammanfattning av artikeln “Knowledge Management in the Fourth Industrial Revolution” – Fakhar m.fl. 2021
Fakhar med flera (2021)1 klargör att automatisering och digitalisering av kunskapshantering inom verksamheter är en central del för att möjliggöra industri 4.0 och bygger på en genomgång av 90 forskningsartiklar över en femårsperiod (2014–2019) som berör nyckelorden industri 4.0 (industry 4.0) och kunskapshantering (knowledge management). Författarna har identifierat ett gap i litteraturen som behöver beforskas och utvecklas beroende på den exponentiella mängden ostrukturerade data nästa paradigm av industrialisering medför, vilket kommer överväldiga dagens informationssystem. Detta kommer starkt begränsa nyttoeffekterna av framväxande teknologi inom industrin och behovet av kunskapsutbyte mellan maskin-maskin och maskin-människa som behövs för att skapa självreglerande och automatiserade system för att exempelvis presentera och uppmärksamma människorna i systemet om betydelsefull information som behövs i beslutsfattandet. Därför anser författarna att mer forskning och utveckling behövs för att lösa utmaningar med att möjliggöra interoperabilitet för vidareutnyttjande av data och information, och sömlös överföring av explicit kunskap som relativt enkelt kan lagras, överföras och förmedlas; samt implicit kunskap – exempelvis att lära sig ett språk, spela ett instrument eller magkänsla grundad i erfarenhet, intuition och vishet, som är svåra att lagra, förmedla och överföra. Detta är grundläggande för att länka samman industrier (maskin till maskin) och samhälle (maskin till människa) för att skapa intelligent automatisering, förstärkta verkligheter (augmented reality), självreglerande system med mera. Litteraturgenomgången presenterar sex kluster som berör teknologi och kunskapshantering som behöver utvecklas för att realisera nyttoeffekterna industri 4.0. utlovar.
Studien genomförde en bibliometrisk analys av nyckelord i litteraturgenomgången, där varje punkt i bild 1 nedan representerar nyckelord som återkommer i minst två olika artiklar. Färgen på de större bubblorna representerar vilket kluster dessa tillhör. Avståndet mellan nyckelorden motsvarar frekvensen av deras samtidiga förekomst.

- Grönt kluster: består av cyberfysiska (cyber-physical) system samt övervaknings- och felhanteringssystem (condition monitoring). Cyberfysiska system är en integration av fysiska processer och inbyggda datorsystem som fungerar som en helhet genom kommunikation, beräkning och interaktion mellan den fysiska och virtuella världen. Exempel på cyberfysiska system är självkörande bilar, robotkirurgi, intelligenta byggnader och elnät med mera. Felhantering och övervakning (condition monitoring) av cyberfysiska system behöver göras proaktivt med hjälp av predicering i realtid för att lösa problem innan de uppstår i maskiner och processer för att motverka ineffektivitet och stopp av produktion. Detta kräver intelligent automatiserad övervakning för att hantera stora datamängder som komplexa system genererar, som tillsammans med exempelvis interaktiv teknologi och algoritmer kan bistå och presentera relevant information till rätt beslutsfattare vid rätt tidpunkt. Från ett kunskapshanteringsperspektiv behövs forskning för att utveckla och förbättra övervakningssystem, lagra kunskap i digitalt format och standarder för att kumulativt bygga och överföra kunskap inom och mellan cyberfysiska system.
- Turkost kluster: Digitala processer behövs för att utvinna kunskap ur stora ostrukturerade datamängder genom kodifiering, personifiering och representation för att bättre tolka och tyda Big Data. Big Data består av ostrukturerade data som i sig kan vara värdefullt genom att tillämpa mönsterigenkänning teknologi. Däremot belyser artikelförfattarna (Fakhar mf.l 2021) vikten med att applicera digitala processer för att utvinna kunskap ur stora ostrukturerade datamängder genom kodifiering, personifiering och representation för att bättre tolka och tyda data. Detta är inte bara betydelsefullt för utvinning av kunskap utan kan också bidra till att stödja verksamhetens innovationsarbete. Flera av de artiklar som studien refererar till använder semantisk teknologi för att berika och kodifiera ostrukturerade data med information och koppla det till verksamhetsbegrepp och processer. Bland annat belyser studien möjligheten att skapa verksamhetsmodeller och ontologier baserade på semantisk teknologi för att deduktivt utvinna kunskap från både historiska och aktuella mängder ostrukturerade data. Från ett kunskapshanteringsperspektiv åskådliggör studien behovet av vidare forskning av metoder och processer för att fånga, tillämpa och skapa ny kunskap ur ostrukturerade datamängder för att uppnå konkurrensfördelar.
- Purpur kluster: utgörs av intelligenta fabriker (smart factory) där forskningsartiklar om digital och hållbar produktion och digitala tvillingar ingår. Intelligenta fabriker är inte begränsade till automatisering med robotar i vanliga produktionskedjor, utan refererar till den potential som uppstår när cyberfysiska system kopplas ihop med informationsteknologi för att möjliggöra snabba produktion- och designförändringar (engineering-reengineering). Exempelvis kan produktion- och designförändringar påverkas av förändring i kundefterfrågan, optimeringsbehov av försörjningskedjor, förändring av regler/praxis som påverkar självreglerande system, återanvändning och recirkulering av fysiska resurser, med mera. Digitala tvillingar är den tydligaste realiseringen av konceptet intelligent fabrik, i form av en virtuell presentation av fysiska produktionskedjor och resurser mellan underliggande fysiska och digitala system. Digitala tvillingar är en virtuell kopia av produktionskedjans alla delar, där användaren (ingenjörer) kan modellera och designa om hela eller delar av produktionen som simulering eller i verkligheten. Tillämpning av intelligenta fabriker i form av digitala tvillingar kan möjliggöra skapandet av ny kunskap kring produktionskedjor för att uppnå effektivitet, koordinering av processer, säkerhet, användarvänlighet, skalbarhet med mera och är områden som behöver utvecklas. Från ett kunskapshanteringsperspektiv belyser studien behovet av forskning för att integrera affärsmodeller i kontexten av intelligenta fabriker.
- Gult kluster: representerar sakernas internet (Internet of Things) som kopplar ihop smarta enheter, sensorer, inbyggda system, maskininlärning med mera. Sakernas internet är en central del av arkitekturen för industri 4.0. som bland annat innefattar Big Data, intelligenta fabriker, cyberfysiska system och det sömlöst vidareutnyttjande av data och information. Sakernas internet bygger på teknologi där varje uppkopplad sak och objekt behöver en unik identifierare och semantisk betydelse för att tolkas och tydas över bransch, organisations- och landsgränser. För att möjliggöra mer komplexa kunskapsflöden belyser studien (Fakhar mf.l 2021) betydelsen av mer innovativa tillämpningar av teknologin för digital kunskapshantering inom och mellan organisationer. Detta för att sakernas internet är den mest betydelsefulla teknologin för att möjliggöra kunskapshanteringsprocesser och system genom att sammanlänka alla uppkopplade saker och ting som innefattar lagring, bearbetning, analysering, visualisering av data, information och hur det kan vidareutnyttjas mellan samarbetspartners. Sakernas internet bygger vidare på teknologi som ligger till grund för den decentraliserade webben och studien lyfter att forskning och utveckling om att web of things/objects är viktigt för att möjliggöra interoperabilitet med hjälp av semantisk teknologi. Studien visar på behovet att vidareutveckla öppna standarder för att möjliggöra automatisk integrering av mikrotjänster, samt plattformar som hanterar och vidareförmedlar data från sakernas internet. Detta för att råda bot på dagens manuella integrering av data och informationssystem som till stor del bygger på informella adhoc baserade standarder som omöjliggör vidareutnyttjande av data, information och kunskapsöverföring. Studien föreslår mer forskning inom öppen innovation för att driva teknologi, arkitektur och standarder kopplat till sakernas internet.
- Rött kluster: består av dels adaptiva och sammankopplade värdekedjor, dels för att möjliggöra hanteringen av en komplex global marknad och dels digital transformation för att stärka innovationsförmågan. Studien föreslår forskning som utreder frågan om hur kunskapshantering inom verksamheten kan stödja möjliggörandet av strategisk flexibilitet och affärsmodellsinnovation.
- Blått kluster: berör artiklar om produktionsprocesser och modellering som med hjälp av förstärkt verklighet (augmented reality) och återkopplingssystem för att förbättra beslutsstöd. Detta för att exempelvis operatörer kan flytta fokus från behandling av data och information till beslut, med hjälp av bättre interaktion med processystem. Förslag på forskningsområden är utvecklingen av processmodelleringsspråk för att integrera processystem med kunskapshanteringssystem.
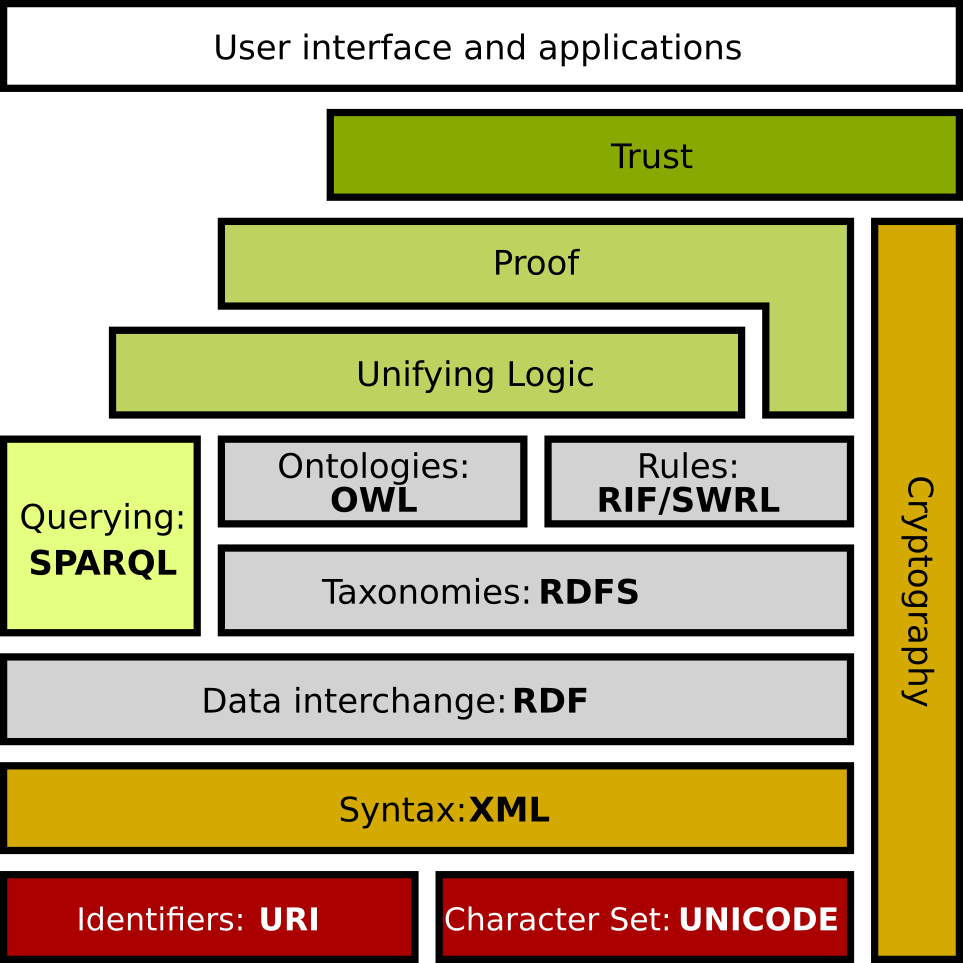
Som en del av analysen kombinerade författarna fem kunskapshanteringsprocesser kopplade till de olika klustren för att svara på frågan om hur teknologiutvecklingen kommer påverka kunskapshantering i framtiden. Första processen är kunskapsinhämtande-kunskapsförvärv av explicit och implicit kunskap. Denna process förekommer i turkost och purpur kluster. Teknologin som tas upp i litteraturen kopplat till denna kunskapsprocess är digitala tvillingar, semantisk webbteknologi och språkregelstandarder, som exempelvis OWL (Web Ontology Language).
Den andra processen är kunskapdokumentering, vilket relaterar till lagring, behörighet och tillgång av kunskap i verksamhetssystem. Teknologi och metodologi som tas upp i litteraturen berör digital transformation för att möjliggöra vidareutnyttjande av kunskap i verksamheten och cyberfysiska system, vilket berör det röda och gröna klustret. Den tredje processen är överföring och utbyte av explicit och implicit kunskap mellan medarbetare inom och mellan organisationer. Denna process förekom i 66 procent av artiklarna i litteraturgenomgång och berörde alla kluster för att möjliggöra kunskapsöverföring. Den fjärde processen utgörs av kunskapsskapande processer som innefattar aktiviteter som stödjer utveckling av ny explicit och implicit kunskap inom organisationen. Ungefär hälften av alla artiklar berörde processen inom övervakning- och felhanteringssystem i grönt kluster och processmodellering av produktionskedjor i purpur klustret. Femte och sista processen är kunskapstillämpning, det vill säga utvinning av praktisk nytta från tidigare kunskapshanteringsprocesser i verksamheten. Denna aktivitet återkom endast i 16 procent av artiklarna och fokuserade på användarbaserad innovation och tillämpning inom turkost kluster – Big Data.
Avslutningsvis klargör författarna hur deras resultat av litteraturgenomgången påverkar verksamheters framtida konkurrenskraft. Detta är några exempel på områden som behöver beforskas och utvecklas enligt studien:
- Bättre kunskap och systemstöd för att tillhandahålla rätt information vid rätt tillfälle i beslutsprocessen
- Delaktighet i öppna innovationsprocesser för utbyte av kunskap och information inom och mellan verksamheter vilket kan stimulera tillämpning av framväxande teknologi och innovation
- Processmodelleringsspråk för att hantera komplexa processmodeller inom produktionskedjor för att möjliggöra kontinuerlig utveckling och förbättring mellan modell och verklighet
- Språkregelstandarder; Web Ontology Language (OWL) och liknande standarder som möjliggör skapande av ontologier och taxonomier för att beskriva verksamhetskunskap och begreppsmodeller i digitalt format.
Sammanfattning av artikeln ”Digital Transformation and Innovation Management” – Appio m.fl 2021
Appio med flera andra författare (2021)2 belyser i sin redaktionella forskningsartikel (editorial edition) de invecklade relationerna mellan digital transformation, innovation och vad som drivit den digitala utvecklingen det senaste decenniet. Artikeln presenterar resultatet uppdelat på tre nivåer: makro, meso och mikro för hur framväxande teknologier, digital innovation, affärsmodellsutveckling, digital entreprenörskap med mera möjliggjort digital transformation och innovation.
På makronivå belyser författarna behovet att verksamheter positionerar sig, deltar i det digitala ekosystemet för kollaborativt samarbete över sektorer och länsgränser i syfte att skapa mervärde för slutanvändare och möjliggör konkurrenskraft. Delaktighet i digitala ekosystem bygger meritokrati, tillit, gemensam kultur och målsättning genom att öppet dela resurser, idéer och kunskap. Det skiljer sig mot föregående paradigm av partnerskap som styrdes av kontraktuella strategiska allianser, och förlitade sig på avtal för att reglera, skydda resurser och idéer inom samarbetet.
På mesonivå ligger fokus på hur verksamheter strukturerar resurser, strukturer och förmågor för att möjliggöra kollaborativt samarbete och samskapande (co-creation) med aktörer i det digitala ekosystemet för att arbeta i varandras processer, utbyta data och kunskap för att samproducera produkter och tjänster. Forskningslitteraturen benämner denna struktur som formbar organisationsdesign vilket kortfattat syftar till förmågan att strukturera om och harmonisera verksamhetens resurser och strukturer för att samarbeta med en mångfald av aktörer för att skapa mervärde på en turbulent digital marknad.
På mikronivå är fokus på person- och gruppnivå inom verksamheter och hur man organiserar och fortbildar personal för att balansera mellan att profitera på existerande digitaliseringsförmåga eller exploatera framväxande digital teknologi för att bygga nya förmågor och avvika från befintlig affärsmodell. Detta möjliggör att verksamheter som genomgått en digitaliseringstransformation kan arbeta med digital transformation och förflytta fokus till att möjliggöra strategisk flexibilitet och kontinuerligt arbeta med affärsmodellsinnovation.
Vad redaktionella forskningsartikeln belyser för alla tre nivåer är att forskningen behöver identifiera och förtydliga hur bestående mervärden kan uppnås på längre sikt via kollaborativa samarbeten mellan en heterogen aktörsgrupp som består av allt från enskilda personer, SME:er, institutioner, verksamheter över sektorer och landsgränser.
Interoperable Europe – europeiska kommissionens regelverk för tvärsektoriell interoperabilitet mellan offentlig, privat och social sektor
Interoperable Europe är en central del EU:s digitala strategi för att säkerställa sömlöst tvärsektoriell datautbyte mellan offentlig, privat och social sektor inom och mellan medlemsländer för att tillgängliggöra medborgarcentrerade digitala tjänster och effektiv förvaltning. Akten för ett interoperabelt Europa är under utveckling och bygger vidare på programmet ISA² som avsluades 2022 och europeiska interoperabilitet ramverket (European Interoperability Framework – EIF) som kommissionen driver för att möjliggöra eGovernment och digital förvaltning. Tillsammans med unionens öppen källkod strategi utgör betydelsefulla komponenter i Europakommissionens målsättning att skapa europeisk digital självständighet.
En intervju med chefen för DG DIGIT (Kommissionens direktorat för informationsteknologi) Leontina Sandu, belyser hon EU:s målsättning för att möjliggöra integrerade digitala tjänster som består av interoperabla byggblock och dataset som kan kombineras för att möjliggöra olika typer av medborgartjänster och digitalt transformera EU. Sandu påpekar att interoperabilitet är svårt och därför behövs det gemensamma insatser inom forskning och tillämpning för att göra det tillgängligt och visa på nyttan genom att visa på flera konkreta exempel.
Thus, interoperability is needed to connect organisations, to make legislation digital-ready and last but not least – to create an ecosystem of integrated digital public services. Such an ecosystem is the basis for digital government and digital transformation.
Leontina Sandu
Den europeiska interoperabilitetsakten hoppas hon skall bli regulatorisk för att realisera kommissionens vision tillsammans med medlemsstaterna för att implementera och utveckla regelverket, där ansvariga digitaliseringsmyndigheter i varje land skall kunna vara med och påverka och utforma policys för att möjliggöra innovation och synergier mellan offentlig, privat och social sektor.
Sandu påpekar att Interoperable Europe inte är något toppstyrt regelverk utan hon uppmanar myndigheter och offentlig sektor att vara med att forma de verktyg och standarder som behövs inom olika sektorer för att möjliggöra interoperabilitet och integrerade digitala tjänster. Förutom regelverk kommer akten även inkludera sandboxmiljöer för innovation och experimentell utveckling. Hon uppskattar att integrerade digitala tjänster kan spara upp till 25 procent i tid för medborgare i interaktionen med myndigheter och offentlig sektor, och en kostnadsbesparing av 0,4 procent av BNP på nationell nivå.
Tidigare FOI med koppling till förstudien
Tidigare FOI projektet metod för samverkan och värdeskapande öppna data syftade till att synliggöra mekanismer som ger upphov till mervärde i data- och informationsutbytet mellan Trafikverket och samarbetspartners. Projektet innefattar en studie där tågoperatörer och kollektivtrafikbolag som benämns avtalskunder, ger sitt perspektiv på värdeskapande mekanismer i sitt strategiska samarbete med Trafikverket. Studien genomförde tolv intervjuer hösten 2016 och många av de utmaningar som respondenterna ger uttryck för i samarbetet med Trafikverket är fortfarande aktuella och relevanta för temat ”nästa generations beslutsstöd”. Frågeställningen var att undersöka avtalskunders perspektiv på Trafikverkets förmåga att skapa mervärde inom partnerskapet och hur detta eventuellt påverkar andra typer av samarbete vid nyttjande av datatjänster. Studien presenterade tre globala värdeskapande mekanismer, interoperabilitet, kongruenta strukturer och synergiskapande förmågor. Nedan följer en kort redogörelse av mekanismerna och kopplingar till temat ”nästa generations beslutsstöd”. Kopplingen till andra studier som presenteras i rapporten är inte vetenskaplig utan visar på beröringspunkter mellan studier.
Interoperabilitet
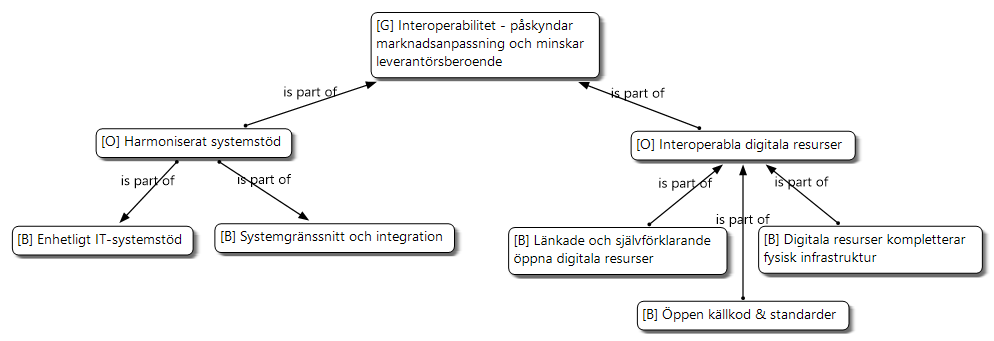
Interoperabilitet återspeglar behovet av IT-infrastruktur som gör det möjligt att dela, kombinera och vidareutnyttja digitala resurser på ett standardiserat tillvägagångssätt. Interoperabilitet innefattar en flexibel IT-infrastruktur som gör det möjligt att sömlöst utbyta och kombinera digitala resurser mellan samarbetspartners utan anpassning. Avtalskunder beskriver en brist på interoperabilitet i form av att IT-infrastrukturen och IT-stödet som används inom samarbetet är fragmenterat. Detta utgör hinder vid exempelvis trafikavvikelser eftersom utbytet av information sker manuellt, där trafiksamordnare måste kopiera information mellan IT-stödsystem, samt ringa och använda e-post och chattkanaler för att koordinera ersättningstrafik. Avtalskunder efterfrågar bland annat självförklarande digitala resurser för att underlätta vidareutnyttjande av data och information så systemstöd kan tolka och tyda data på ett enhetligt sätt för att exempelvis skapa en gemensam lägesbild vid trafikavvikelser. Den manuella hantering och tolkning av information mellan systemen som görs idag tar tid och är föremål för den mänskliga faktorn när många saker sker samtidigt. Självförklarande digitala resurser kopplar an till artikeln av Fakhar med flera (2021) om att utforska hur språkregelstandarder som Web Ontology Language (OWL) och liknande standarder kan användas för att möjliggöra ontologier och taxonomier för att beskriva verksamhetskunskap och begreppsmodeller i digitala format.
… vi får lägga väldigt mycket tid för att manuellt tyda vad vissa objekt betyder eftersom data inte är strukturerat på samma sätt vilket gör att det kan tolkas på olika sätt i olika system.
Avtalskund
Flera av avtalskunderna ser digitala resurser kopplade till järnvägsinfrastrukturen som en del av ett större transportsystem. För att få bättre utväxling av investeringar i fysisk infrastruktur menar respondenterna att det behövs ett digitalt lager som skapar bättre förståelse för alla inblandade parter om exempelvis underhållsstatus, utnyttjandegrad och flaskhalsar. Litteraturgenomgången av Fakhar med flera (2021) lyfter behovet av forskning och utveckling av digital hållbar produktion och digitala tvillingar för att möjliggöra en virtuell presentation av fysiska produktionskedjor som innehåller fysiska och digitala system. Detta i syfte att realisera tillämpning av intelligenta fabriker och möjliggöra skapande av ny kunskap kring produktionskedjor för att uppnå effektivitet, koordinering av processer, säkerhet, användarvänlighet, skalbarhet med mera.
… för att få utväxling för investeringarna i metallen och betongen vi gräver ner så behöver vi också lägga på det här lagret ovanpå.
Avtalskund
Interoperabilitet är ett globalt tema bestående av två underliggande organiserande teman Interoperabla digital resurser, och Harmoniserat systemstöd. Bild 2 nedan visar globala teman med prefixet [G], organiserande med [O] och grundläggande med [B] (basic) som innehåller citat från avtalskunder.
Kongruenta strukturer
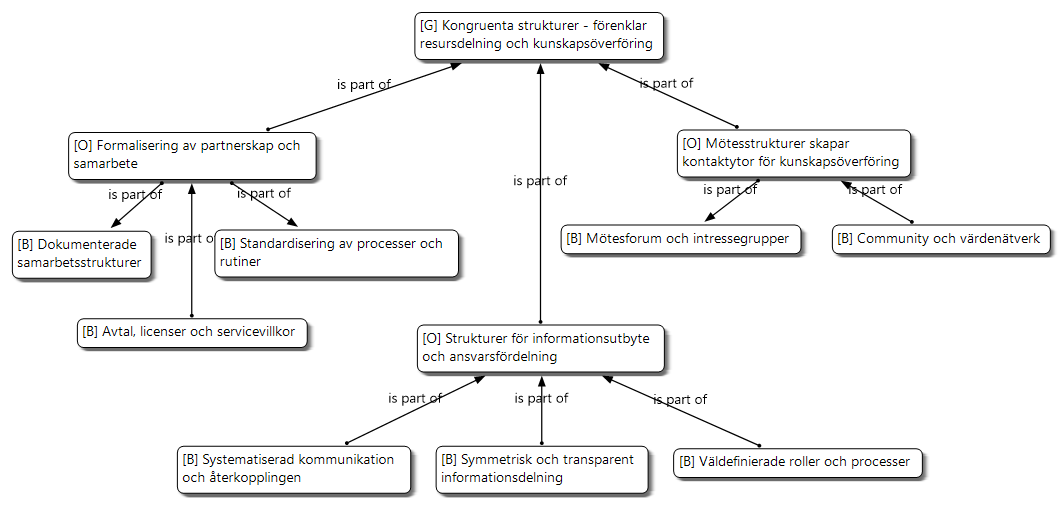
Kongruenta Strukturer syftar på hur väl verksamheten är organiserad för att samarbeta och skapa mervärde i samarbete med andra aktörer. Mekanismen avser hur väl anpassade verksamhetensstrukturerna är för att samarbete med olika typer av aktörer för att snabbt och effektivt genomföra beslutsprocesser, förändringsprojekt, samt absorbera och överföra kunskap mellan parterna. En struktur som identifierats i studien är behovet av systematisk och transparent informationshantering för beslutsfattandet inom partnerskapet. Problemet som tas upp är bland annat att generella informationskanaler såsom e-post, chatt och telefon används i stor utsträckning, vilket resulterar i att information blir ostrukturerad och svår att återanvända för olika ändamål. Avtalskunder efterfrågar bättre strukturer för scenario- och behovsbaserat informationsutbyte eftersom dagens systemstöd bidrar till ett informationsöverflöd vilket försvårar koordinationen av trafikavvikelser då all information sprids till alla aktörer oavsett om det är relevant för deras situation eller inte. Problemet med informationsöverflöd och stora mängder ostrukturerade data (Big Data) är något som Fakhar med flera (2021) presenterar som imperativt för att realisera nyttoeffekter som utlovas med industri 4.0. Avtalskunderna i studien upplever denna problematik i sitt dagliga arbete med informationssilor och systemstöd som inte kan vidareutnyttja data och information mellan varandra.
Ett annat perspektiv på systematisering av interaktion och kommunikation är att ta vara på feedback från partners och användare på ett mer strukturerat sätt för att arbeta med kontinuerligt kvalitetshöjande åtgärder. Avtalskunder efterfrågar ett strukturerat arbetssätt för att tillvarata återkoppling från samarbetspartners för att höja kvaliteten på informationstjänsterna. Återkoppling och feedback är också betydelsefullt för systematisering av övervakning och felhanteringsövervakning (condition monitoring) som tas upp i Fakhar med fleras artikel (2021) av cyberfysiska system. Detta är betydelsefullt för att proaktivt reducera fel med hjälp av predicering i realtid för att lösa problem innan de uppstår i maskiner och processer för att motverka ineffektivitet och stopp av produktion.
… feedback på data gör att kvaliteten höjs och vi får också fler smarta förslag på lösningar som kommer kunderna till nytta.
Avtalskund
Kongruenta strukturer är ett globalt tema bestående av tre underliggande organiserande teman: Formalisering av partnerskap, Strukturer för informationshantering och Mötesforum för kunskapsöverföring. Bild 3 visar globala teman med prefixet [G], organiserande med [O] och grundläggande med [B] (basic) som innehåller citat från avtalskunder.
Synergiskapande förmågor
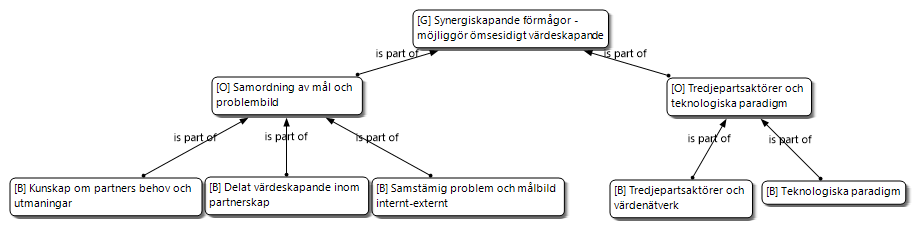
Synergiskapande förmågor belyser behovet av god insikt i samarbetspartners verksamheter för att förena gemensamma mål och nyttja varandras resurser på ett sätt som ger upphov till synergier. Parten som leder och koordinerar samarbetet behöver bland annat besitta förmågan att förutse kommande behov inom samarbetet. För detta krävs kontinuerlig uppdatering av parternas behov och målbild, och beskrivs av avtalskunder som ”fingertoppskänsla”. Exempelvis refererar avtalskunder till ett stort förändringsprojekt inom kapacitetsplanering, som enligt den ursprungliga kravspecifikationen skulle leda till att viktiga processer och integrationer skulle sluta fungera. Tack vare avtalskunders krav på delaktighet i projektet skapades en fördjupad insikt av varandras behov och målbilder, vilket i sin tur möjliggjorde ömsesidiga mervärden genom att interna och gränsöverskridande processer kunde skärskådas och harmoniseras mellan parterna.
Förmåga att skapa synergier innefattar insikt i samarbetspartners behov och utmaningar för att genomföra förändringsarbete som leder till ömsesidiga mervärden tack vare samstämmiga mål och problembilder. Detta ställer krav på upparbetade förmågor att kontinuerligt vara uppdaterad och förutse kommande behov för att proaktivt arbeta med att upprätthålla ett värdeskapande partnerskap. Att hitta gemensamma nyttor och utveckla kunskap om varandras verksamheter beskrivs av flera avtalskunder som centralt för att utveckla branschsamarbetet. Samtidigt måste nya initiativ se till att beskriva vilka fördelar olika samarbetspartners kan förvänta sig av förändringsarbeten.
Då vill man så tidigt som möjligt se vilka förutsättningar vi har, att faktiskt hitta någonting som båda parter kan dra nytta av.
Avtalskund
För att möjliggöra synergier ser avtalskunder också behovet att utnyttja egenskaper som ny teknologi erbjuder och tillämpa nya tankemönster i branschen för att hålla jämna steg med den digitala utvecklingen. Detta genom att utnyttja och tillämpa teknologier för att uppnå verksamhetsmål. För att skapa liknande förmågor förespråkas att man inom samarbetet börjar laborera och utforska möjligheterna med ny teknologi i mindre skala, för att i ett senare skede tillämpa teknologierna när verksamheten är mogen.
Vi kan börja med någonting litet … som blir en positiv spin-off och då våga ta ett större steg …
Avtalskund
Synergiskapande förmågor är ett globalt tema bestående av två underliggande organiserande teman: Samordning av mål och problembild och Teknologiska paradigm och värdenätverk. Bild 4 (nedan) visar globala teman med prefixet [G], organiserande med [O] och grundläggande med [B] (basic) som innehåller citat från avtalskunder.
Sammanfattning
Genomgång av forskningslitteratur (Fakhar m.fl., 2021) som berör industri 4.0 och kunskapshantering (knowledge management) identifierar sex olika teman av teknologiska koncept där kunskapshantering behöver utvecklas för att möjliggöra mervärde och digitalt transformera industrin. Litteraturgenomgången har paralleller till FOI studien – Metod för samverkan och värdeskapande öppna data (2016), som visar på mekanismer som har inverkan på Trafikverkets förmåga att tillhandahålla värdeskapande datatjänster för avtalskunder. Studien identifierar tre övergripande mekanismer: interoperabilitet, kongruenta strukturer och synergiskapande effekter, som inverkar på avtalskunder inom tåg och kollektivtrafiken, och som är beroende av Trafikverkets datatjänster för att bedriva sin verksamhet. Mekanismerna i studien har implikationer på temat ”nästa generations beslutsstöd”, då det är liknande förmågor och strukturer som behövs för att sömlöst möjliggöra utbyte av data, information och kunskapsöverföring med andra samarbetspartners till Trafikverket.
Den redaktionella forskningsartikeln Digital Transformation and Innovation Management av Appio med flera (2021) belyser också betydelsen av strukturer och förmågan att hantera innovationsprocesser, samt utbytet av kunskap och idéer över organisationsgränserna för att möjliggöra digital transformation. Artikeln har kopplingar till förstudien ”Inkluderande digital samhällsutveckling och delaktighet i öppna innovationsprocesser” som belyser Trafikverkets och transportsystemets behov att vara delaktiga i kollaborativa samarbeten med andra aktörer i det digitala ekosystemet. Detta i syfte att ta del av de synergieffekter som uppstår i liknande partnerskap där flera aktörer från olika branscher säkerställer anpassningsbarhet, kvalité, säkerhet och interoperabilitet vid utveckling av mjukvara och digital infrastruktur3. Förstudiens genomgång av forskningslitteraturen för en enhetlig beskrivning av digital transformation belyser behovet av egna digitaliseringsförmågor, formbara organisationsstrukturer och värdefulla digitala resurser för att delta i distribuerade innovationsprocesser för att målmedvetet styra kunskapsflöden över organisationsgränserna.
Mötet för presentationen av bidrag till temat ”nästa generations beslutsstöd” för kommande FOI plan, målade talare och deltagare upp en likartad bild av betydelsen av digitaliserings- och digital transformation för att vidareutnyttja data, information och kunskapsöverföring mellan forskningsområden, utveckling inom stadsplanering, mobilitet, samhällsutveckling, åtgärdsvalsstudier, innovationsresor med mera.
Studien Interoperabel data- och informationsförsörjning mellan samhällssektorer för omdömesgilla beslutsstöd, ser behovet av mer aktionsforskning – kombination av forskning och utveckling, för att laborera, utbyta idéer och kollaborativt samarbeta med en mer heterogen aktörsgrupp inom och utanför transportsystemet för att hitta lösningar på samhällsutmaningar. Där det är betydelsefullt att harmonisera målsättning och initiativ för att möjliggöra vidareutnyttjande av data och information, digital kunskapshantering baserat på öppna standarder och demokratiska principer i samarbete med andra sektorer och nationer inom EU. Vidare tematisk indelning av utmaningar och konkreta förslag på lösningar är svåra att föreslå utifrån det generella temat ”nästa generations beslutsstöd” utan att vidare specificera vad temat innefattar och definiera problemområdet. Däremot lyfter denna studie, på ett mer övergripande plan nödvändigheten att skyndsamt genomföra digitalisering och digital transformation för att samarbeta med övriga samhällssektorer och branscher som redan har eller är på väg att transformeras om Trafikverket och transportsystemet skall vara delaktiga i den digitala utvecklingen. Detta eftersom ingen bransch är immun mot det externa sociotekniska förändringstryck som digital disruption samt uppkomst och spridning av ny digital teknologi medför.
 Källa:
Källa: